![]()
![]()
![]()
![]()
Proteins are biologically very important as they are the executive biomolecules in cells, tissues and organs. In this context, proteomics involves the parallel identification, quantification, and spatial resolution of many proteins in complex samples. Proteomics experiments with a focus on clinical research are indispensable for a comprehensive understanding of biological functions and diseases of high socio-economic relevance for aging societies, such as neurodegenerative diseases, metabolic diseases and cancer.
The Core Facility for Bioinformatics at the Faculty of Medicine "CUBiMed.RUB" at the Faculty of Medicine offers a wide range of tools, services and trainings in the context of bioinformatics for proteomics.
The staff of the research area "Medical Bioinformatics" of the MPC has extensive expertise and experience in the development and application of proteomics tools and resources, statistical analysis, and the application of machine learning methods. Here, the focus is primarily on clinical and human proteomics.
Consulting and analysis services are offered free-of-charge (for scientific users) within the portfolio of the scientific infrastructure facility CUBiMed.RUB to support users in bioinformatics and statistical analysis of proteomics data and associated clinical data. The services are also offered through the German Network for Bioinformatics Infrastructure (de.NBI / ELIXIR-DE), which is funded by the Federal Ministry of Research, Technology and Space (BMFTR, W-de.NBI-005).
Further information and FAQs can be found on the CUBiMed.RUB website: https://www.cubimed.ruhr-uni-bochum.de/faqs/index.html.en
If you have an analysis or consulting request, please contact us directly via cubimed@rub.de.
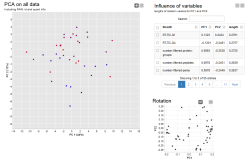
We offer a bioinformatics consulting service regarding the application of our own as well as third-party proteomics software. We advise on data analysis and the selection of suitable software tools. In addition, we develop user-friendly workflows for frequently required analyses and make them available. In addition to the expert advice provided by our bioinformaticians, we also offer to perform the corresponding analyses.
Our services include:
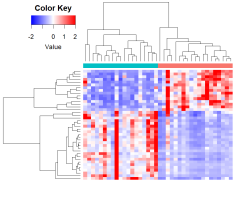
We provide support in the planning of proteomics studies, in the selection of suitable analysis methods and in the interpretation and presentation of the results obtained. In addition to the expert advice provided by our biostatisticians, we also offer to perform the corresponding analyses.
Our services include:
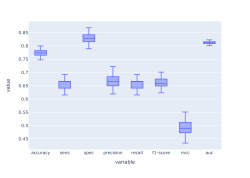
We provide support in the planning and development of machine learning projects with proteomics and corresponding clinical data. From discussing what and how many data points are needed to selecting appropriate algorithms to interpreting model outputs and communicating results, we guide you through every step. In addition to consulting, we also offer to perform machine learning analyses.
Our services include:
Copyright © MPC 2026
Last update: Jan 30, 2026